Render设计报告
一 分数
xxxxxxxxxx------------Score table:--------------------------------------------------------------------------------------| Scene Name | Ref Time (T_ref) | Your Time (T) | Score |--------------------------------------------------------------------------| rgb | 0.2568 | 1.2989 | 4 || rand10k | 2.7831 | 5.0756 | 6 || rand100k | 25.8471 | 25.3968 | 9 || pattern | 0.452 | 1.5589 | 5 || snowsingle | 16.8793 | 2.634 | 9 || biglittle | 15.0092 | 38.1593 | 5 || rand1M | 155.2241 | 21.3826 | 9 || micro2M | 301.3309 | 10.2481 | 9 |--------------------------------------------------------------------------| | Total score: | 56/72 |--------------------------------------------------------------------------即,在多数场景下跟参考实现接近,少数场景完全优于参考实现,少数场景劣于参考实现。
分析:
劣势场景:在图形占有的pixel很多的时候,比如biglittle,rand10k,圆的半径很大,覆盖大量tile,会存在大量的atomicAdd.以及圆分布不均的时候,某些pixel thread工作量巨大。
优势场景:在小圆很多,每个圆覆盖少量tile的时候,重叠不高的时候,计算分布是均衡的。空间局部性好。
二 设计
起因:初始代码为每个cuda线程代表一个圆,然后用参考实现的计算其覆盖的像素并shade。这存在一个问题,同一个像素的不同圆之间存在透明度混合问题:

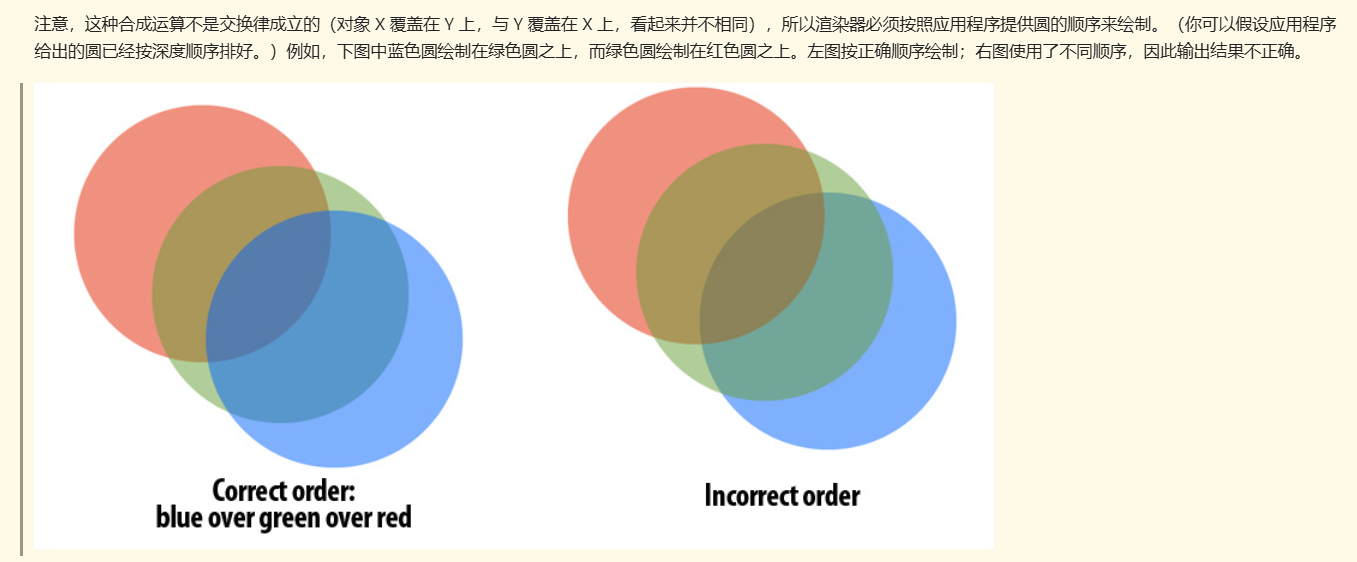
cuda线程之间并没实现同步机制,所以圆的渲染顺序很可能是上面的右图,导致渲染顺序不正确。
所以需要一种并行实现方法,能够保持深度更深的圆先于深度更浅的圆进行像素shade渲染。
思路:很容易想到每个cuda线程负责一个像素的实现方法,因为存储的圆已经预先有序,那么每个像素从头到尾扫描并shade一遍就可以保证顺序。
问题:这种情况下,每个线程都需要扫描所有的圆,当圆的个数接近百万级别的时候,可以发现其实很多圆根本不必要这样计算。此时总工作量为圆的个数乘像素数。这种解法不能正常运行(因为CUDA Kernel有运行时间限制,当这个kernel超出某个时间时,就会被类似于watchdog的东西打断,对linux来说。因为据说GPU还得负责渲染)
思路:将屏幕分为多个tile(在这个实现中是16x16,也就是说16x16pixel作为一个tile,也刚好是代码设置的BLOCK_SIZE=256),首先对所有的圆计算它们覆盖的tile,然后再在BLOCK里面,按照tile里面有哪些圆来进行pixel级别的shade。具体实现如下。当屏幕调用render,进行计算的时候:
对每个圆,计算它们覆盖的tile,使用tileCircleCount进行统计(初始化为全0),即,对圆
对tileCircleCount进行exclusive_scan,计算出
现在有了
tileCircleCount和tileCircleOffset,重新进行类似于第一步的操作,对每个圆circleIdx,它覆盖了的tile集合为
注意操作的原子性,代码里可以这样写
xxxxxxxxxx for (int tileY = tileMinY; tileY < tileMaxY; tileY++) { for (int tileX = tileMinX; tileX < tileMaxX; tileX++) { int tileId = tileY * tileCountX + tileX;
int localIdx = atomicAdd(&tileCircleCursor[tileId], 1); int indicesIdx = tileCircleOffset[tileId] + localIdx; tileCircleIndices[indicesIdx] = index; } }
对每个tile内的
总结
对Count的Scan结果,可以是另一个数组的下标偏移,依旧data-parallel thinking..
预计得回填并行scan的坑了
附录A 伪代码
1 预处理
预处理,记录所有tile所包含的circle的list。
x
parallel foreach circle in circles { calculate tiles that circle overlaps; for t in tiles { tileCount[t]++; }}
exclusive_scan(tileOffset, tileCount);
tileCursor[numTile] = {0};
parallel foreach circle in circles { calculate tiles that circle overlaps; for t in tiles { tileIndices[tileOffset[t]+tileCursor[t]] = circle; tileCursor[t]++; }}2 渲染
x
foreach thread in thread_block/tile { foreach circle in tileIndices[tileOffset[tileId]..tileOffset[tileId+1]] { shade(circle, threadPixel); }}排序可以参考DeviceSegmentedRadixSort,此处略。
附录B 参考资料
stanford-cs149/asst3: Stanford CS149 -- Assignment 3