scan与并行思考 - 其二
问题1 find_repeats
问题描述
输入一个数组
输入样例
x3 4 4 5 6 7 7输出样例
xxxxxxxxxx1 5解释
解法
我们知道串行实现直接push_back即可。
并行实现
可以让每个thread负责一个元素,判断是否跟其下一个元素相等,记录到flag数组

此时我们就得到了下标1和下标5是符合条件的,这个时候就需要回答以下问题:
怎么把这个统计到答案数组?
我们先来看一下串行的实现
xxxxxxxxxxcursor = 0;ans[];for i in 0..n { if flag[i] { ans[cursor++] = i }}并行的实现首先从每个thread负责一个元素/一个下标出发
当flag为真的时候,统计到结果数组,此时可能会考虑到使用一个全局的counter,但是每个线程之间是并行的,你无法确定结果数组的顺序关系,比如上面的,正确答案应该是1 5,并行全局counter的结果可能有1 5,也可能是5 1,后者发生在下标为5的线程先于下标为1的线程写入结果数组时。
exclusive_scan的含义
串行实现的正确性保证来源于其外层for循环的从头到尾偏序性质,我们是否能在并行算法中,找到一种满足递增偏序性质的东西?
答案是exclusive_scan。普通前缀和满足单调不减性质。对于数组
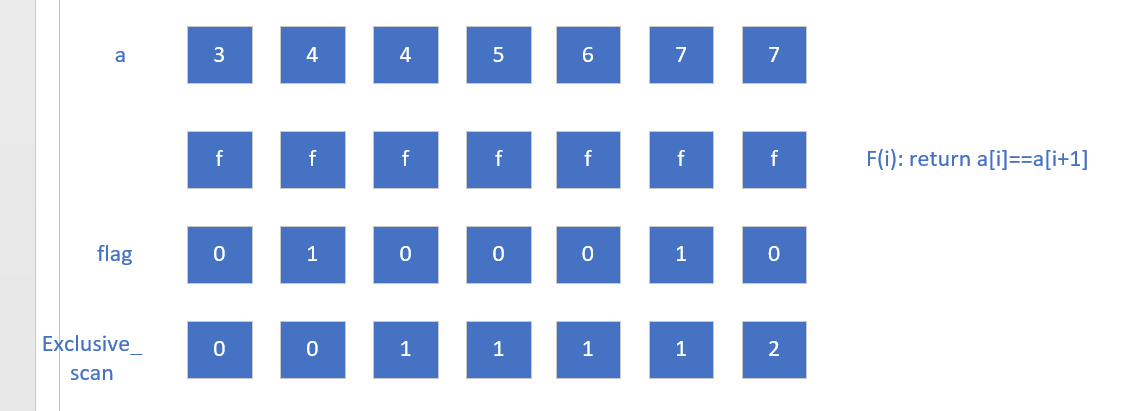
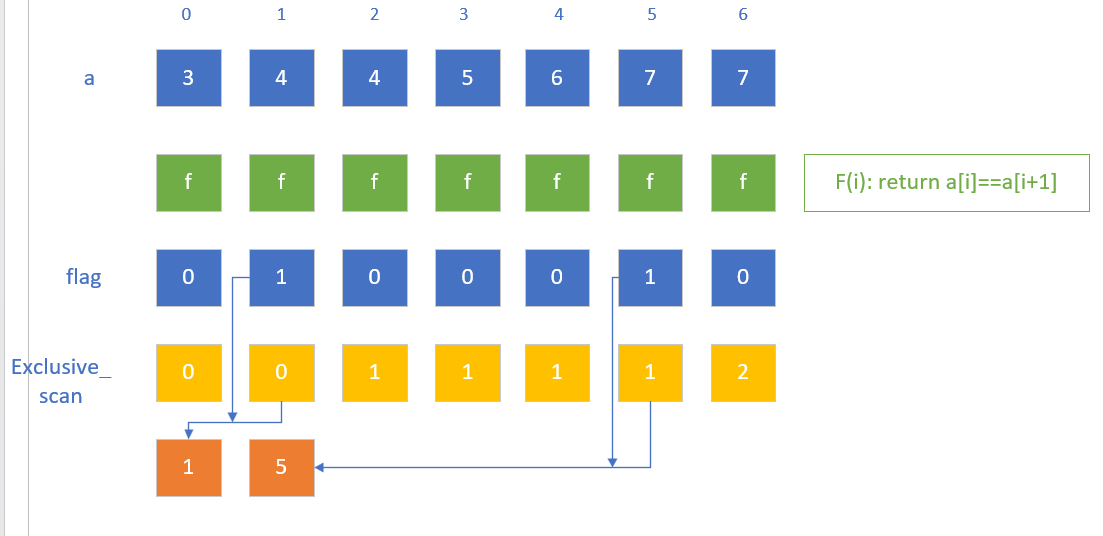
这种情况下,每个线程都可以拥有自己的exclusive_scan数组中的元素,每个元素的值都蕴含着其前面有多少个1的信息,所以可以准确的用来作为结果数组的下标。
然后我们就可以根据这个写出如下代码:
x
foreach thread/i in n { if(flag[i]) { ans[exclusive_scan[i]] = i }}可以发现其实就是类似于scatter的东西

问题2 binning
问题背景
这个是从asst3的render总结出来的,可以去看看那篇render的。render的背景是,对每个圆,统计他们覆盖的tile,然后把这个圆加到对应tile的list里面
所以串行算法大概是
xxxxxxxxxxfor circle in circles { tiles = calculate what circle overlaps; for t in tiles { list[t] += circle; }}关键词
权值统计问题、直方图问题
问题描述
给定一个数组
假设 条件为:第
输入样例
该样例为一种统计数组元素出现次数(权值)的子问题,后续讲解使用类似该子问题进行说明
x
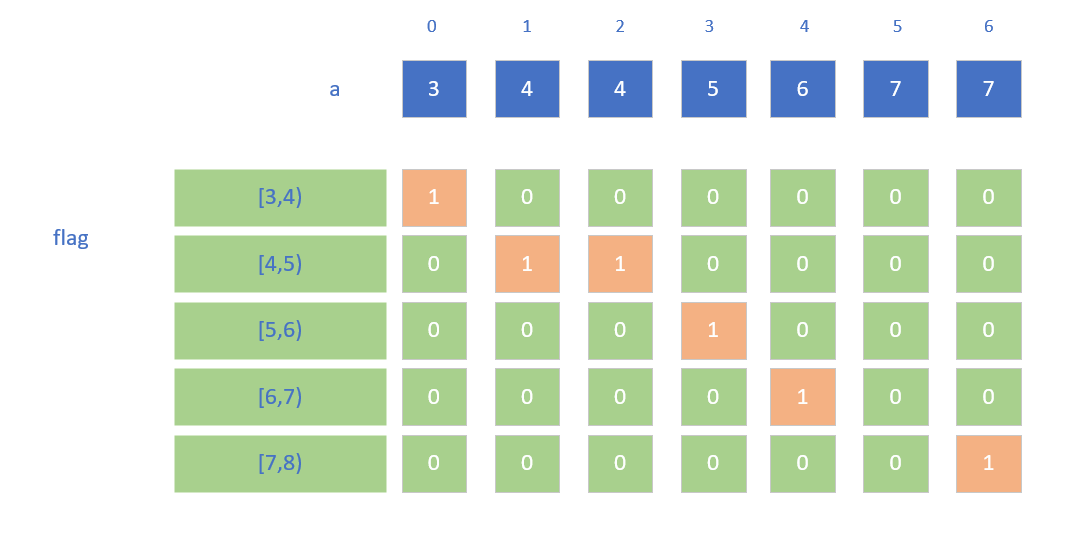
a: 3 4 4 5 6 7 7f:{x >= 3 && x < 4},{x >= 4 && x < 5},{x >= 5 && x < 6},{x >= 6 && x < 7},{x >= 7 && x < 8} 即一共5个桶,分别为对应值域的一种类似直方图的东西。
输出样例
xindex 0 1 2 3 4count 1 2 1 1 2bin{x >= 3 && x < 4} 0{x >= 4 && x < 5} 1 2{x >= 5 && x < 6} 3{x >= 6 && x < 7} 4{x >= 7 && x < 8} 5 6
即输出为
x[[0],[1,2],[3],[4],[5,6]]
串行算法
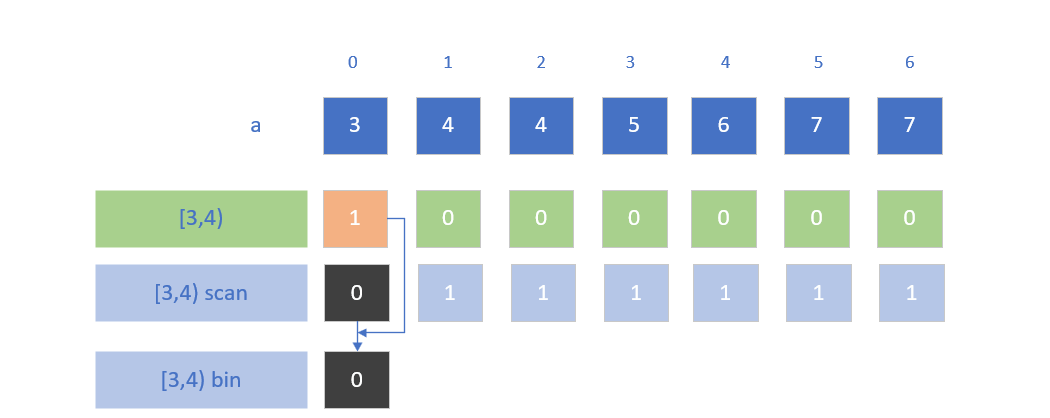
xfor i in 0..n {calculate index of bin that a[i] satisfies (you can enumerate all f, when f(a[i]) = true, the index of f is the answer index);bin[index].append(i)}
类比上例,我们发现每个index的bin都有一个由append维护的cursor[index],在并行中会受到数据竞争的影响导致顺序不固定。
那同样的,我们也使用对于每个条件
这种利用exclusive_scan的方式就是避免了写入cursor的数据竞争
这种解决方式本质上与第一个问题完全一致。
问题扩展
在render的作业中,也许由于本人比较菜不会用cuda分配多维动态数组,所以将bin展开为1维的数组进行维护的。
因此,出现了以下扩展问题:
如何在一维的答案数组
即,输出为将以下的内部中括号作为一种虚拟边界而非实际的二维数组分界线。
xxxxxxxxxx[[0],[1,2],[3],[4],[5,6]]
依然来到串行算法的实现,假设有N个
x
start[N], end[N];// 左闭右开ans[];int cursor = 0;for i,bin in enumerate(bins) { start[i] = cursor; for x in bin { ans[cursor++] = x; } end[i] = cursor;}此时ans[start[i]..end[i]]为
发现
细心的读者可以发现,我在此处将append操作手写为cursor作为索引的操作,可以发现,可以使用类似于第一个问题的解法,用前缀和替代这里的
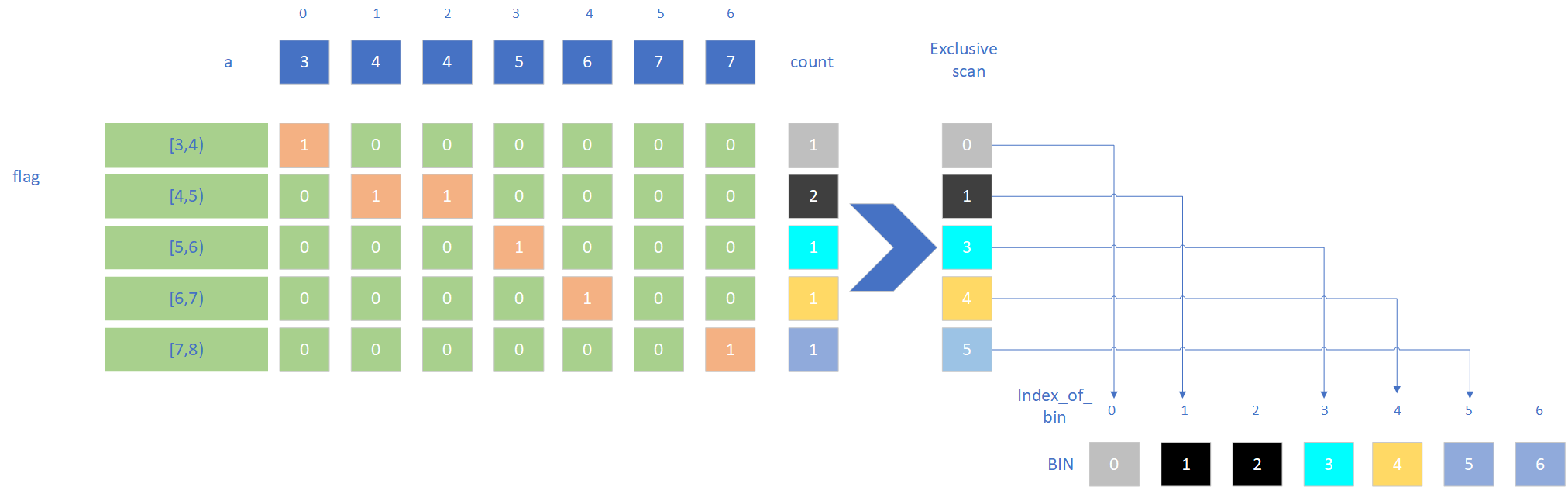
这样得出的每个scan结果,就相当于在答案数组中,这个结果对应的答案的起始偏移。
这个性质也很简单,就是对于exclusive_scan结果的第
就是
注意
并行合并桶的过程中,每个线程代表N个count元素中的一个count元素,这样进行并行的exclusive_scan。时间复杂度、工作量见上一篇文章的分析。
由flag得到count的过程可以使用reduce/fold之类的东西
此时主要得到的是offset,即第几个桶和桶list之间的偏移对应关系,不难发现,在这之后计算答案只需要更改一下第一问的代码
假设a长度为m,一共有n个f,flag[n][m],对每一行flag执行exclusive_scan得出的数组为
对exclusive_scan得出的数组为
那么需要实现的算法如下
x
foreach thread/i in n { foreach j in m { if(flag[i][j]) { ans[index[j]+offset[i]] = j } }}其中两个foreach都可以并行,也可以同时并行。
具体实现时请注意__syncthreads()调用时机。